Run Pairwise Evaluations
Currently, evaluate_comparative is only supported in the Python SDK.
LangSmith supports evaluating existing experiments against each other. This allows you to use automatic evaluators (especially, LLM-based evaluators) to score the outputs from multiple experiments against each other, rather than being confined to evaluating outputs one at a time. Think Chatbot Arena - this is the same concept! To do this, use the evaluate_comparative function
with two existing experiments. If you haven't already created experiments to compare, check out our Quick Start guide or our Evaluations How-To Guide to get started with evaluations.
The evaluate_comparative Function
At its simplest, evaluate_comparative function takes the following arguments:
experiments: A list of the two existing experiments you would like to evaluate against each other. These can be uuids or experiment names.evaluators: A list of the pairwise evaluators that you would like to attach to this evaluation. See the section below for how to define these.
Along with these, you can also pass in the following optional args:
randomize_order: An optional boolean indicating whether the order of the outputs should be randomized for each evaluation. This is a strategy for minimizing positional bias in your prompt: often, the LLM will be biased towards one of the responses based on the order. This should mainly be addressed via prompt engineering, but this is another optional mitigation. Defaults toFalse.experiment_prefix: A prefix to be attached to the beginning of the pairwise experiment name. Defaults toNone.description: A description of the pairwise experiment. Defaults toNone.max_concurrency: The maximum number of concurrent evaluations to run. Defaults to 5.client: The LangSmith client to use. Defaults toNone.metadata: Metadata to attach to your pairwise experiment. Defaults toNone.load_nested: Whether to load all child runs for the experiment. WhenFalse, only the root trace will be passed to your evaluator. Defaults toFalse.
Inputs and Outputs to your Evaluator
Inputs: A list of Runs and a single Example. This is exactly the same as a normal evaluator, except with a list of Runs instead of a single Run. The list of runs will have a length of two. You can access the inputs and outputs with
runs[0].inputs, runs[0].outputs, runs[1].inputs, runs[1].outputs, example.inputs, and example.outputs.
Output: Your evaluator should return a dictionary with two keys: key, which represents the feedback key that will be logged, and scores, which is a
mapping from run ID to score for that run. We strongly encourage using 0 and 1 as the score values, where 1 is better. You may also set both to 0 to represent
"both equally bad" or both to 1 for "both equally good".
Note that you should choose a feedback key that is distinct from standard feedbacks on your run. We recommend prefixing pairwise feedback keys with pairwise or ranked.
Example
The following example uses a prompt which asks the LLM to decide which is better between two AI assistant responses. It uses structured output to parse the AI's response: 0, 1, or 2.
from langsmith.evaluation import evaluate_comparative
from langchain import hub
from langchain_openai import ChatOpenAI
from langsmith.schemas import Run, Example
prompt = hub.pull("langchain-ai/pairwise-evaluation-2")
def evaluate_pairwise(runs: list[Run], example: Example):
scores = {}
# Create the model to run your evaluator
model = ChatOpenAI(model_name="gpt-4")
runnable = prompt | model
response = runnable.invoke({
"question": example.inputs["question"],
"answer_a": runs[0].outputs["output"] if runs[0].outputs is not None else "N/A",
"answer_b": runs[1].outputs["output"] if runs[1].outputs is not None else "N/A",
})
score = response["Preference"]
if score == 1:
scores[runs[0].id] = 1
scores[runs[1].id] = 0
elif score == 2:
scores[runs[0].id] = 0
scores[runs[1].id] = 1
else:
scores[runs[0].id] = 0
scores[runs[1].id] = 0
return {"key": "ranked_preference", "scores": scores}
evaluate_comparative(
# Replace the following array with the names or IDs of your experiments
["my-experiment-name-1", "my-experiment-name-2"],
evaluators=[evaluate_pairwise],
)
In LangSmith UI
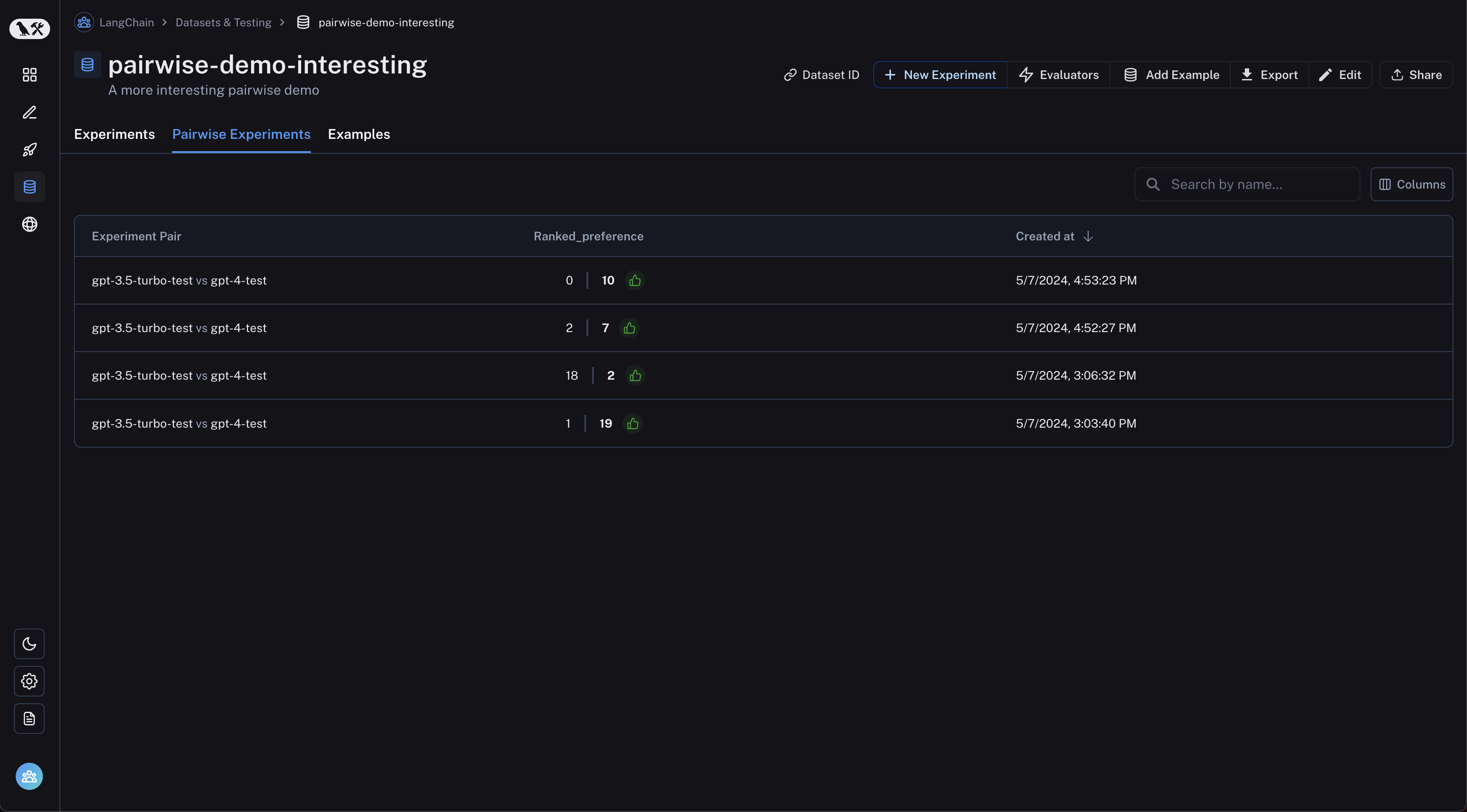
Navigate to the "Pairwise Experiments" tab from the dataset page:
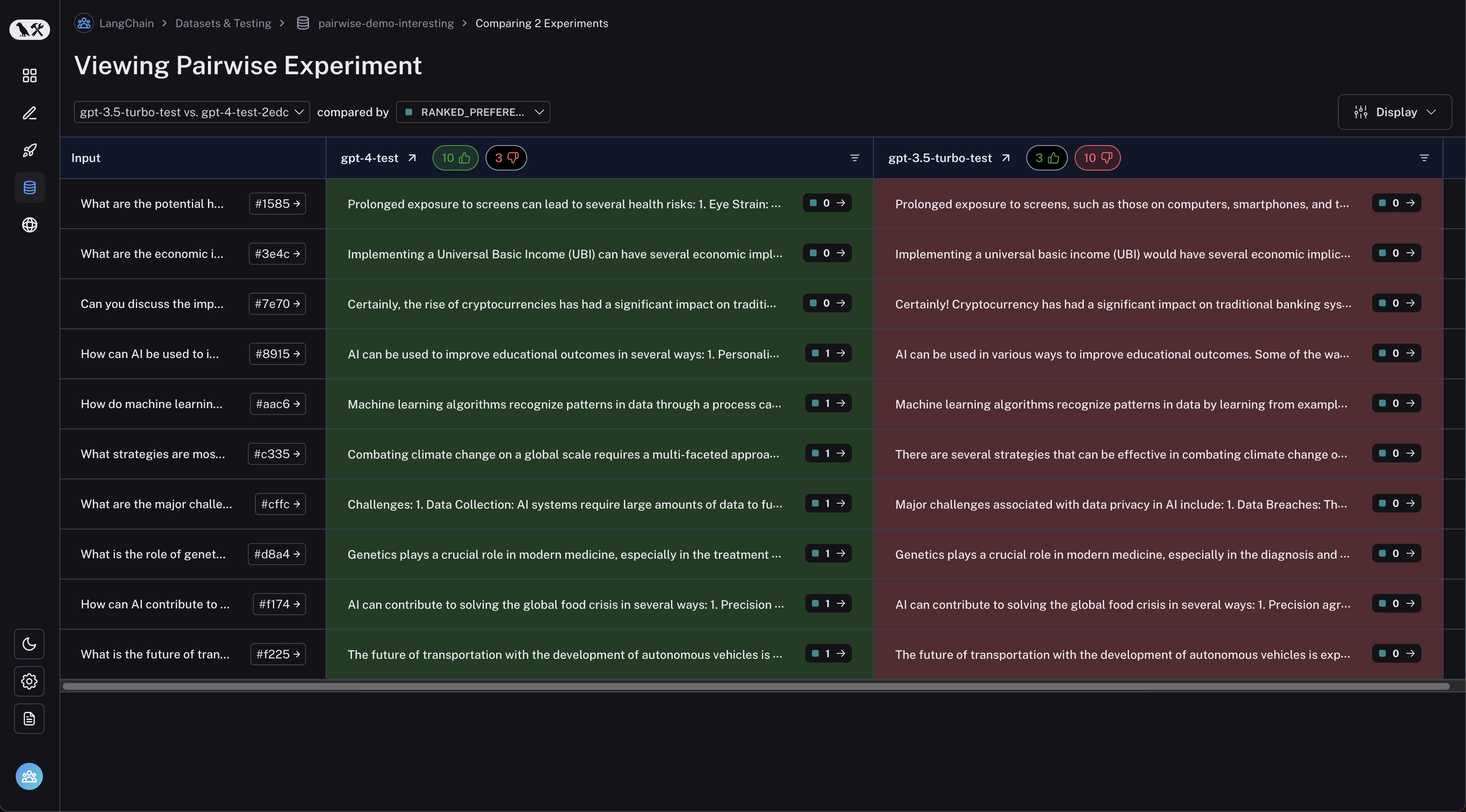
Click on a pairwise experiment that you would like to inspect, and you will be brought to the Comparison View:
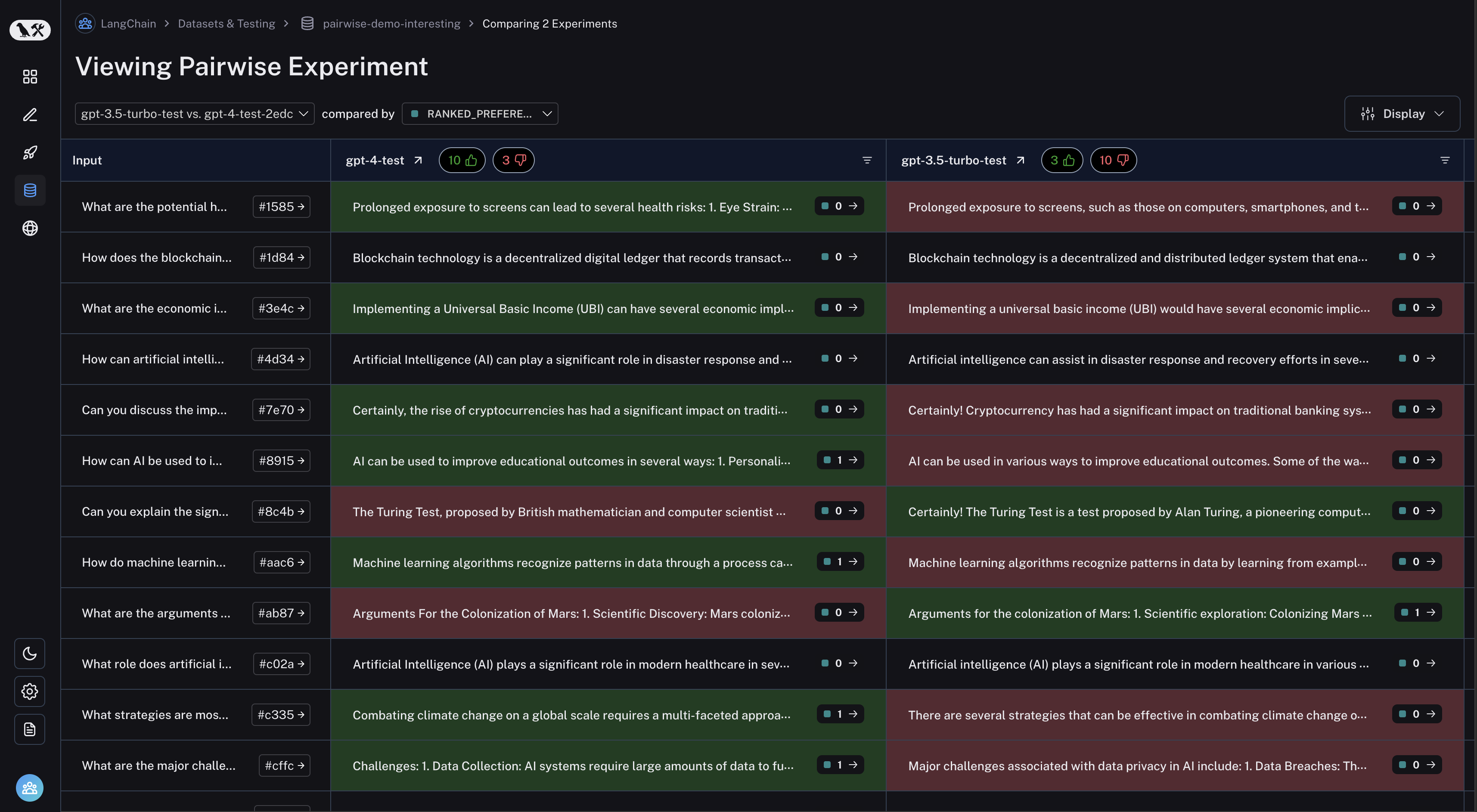
You may filter to runs where the first experiment was better or vice versa by clicking the thumbs up/thumbs down buttons in the table header: